
La mayor parte de la investigación científica se realiza sobre unos pocos casos, extraídos de una población mayor. En muchas ocasiones debemos hacerlo por razones de costo y de tiempo. Piensa por ejemplo en las estimaciones del desempleo que el Instituto Nacional de Estadística reporta mensualmente. Sólo pueden hacerse a partir de muestras. Censar a toda la población económicamente activa del país cada mes resulta imposible por una cuestión de recursos.
En otras sería insensato hacerlo, con independencia de los costos. Las pruebas de efectividad de las vacunas contra el SARS-CoV-2 se hacen en muestras de personas. No tiene sentido vacunar a toda la población para evaluar si las vacunas son efectivas. La idea es saberlo antes de iniciar una intervención planetaria.
En todos los casos existe, sin embargo, una razón adicional de orden técnico: si bien las estimaciones a partir de muestras introducen un tipo de error que llamamos estadístico, toda recolección de datos produce además los llamados errores de medición. Estos ocurren en los propios procesos de recolección de la información. Cuando, por ejemplo, utilizamos un formulario con preguntas (una encuesta nos viene a la mente), distintos modos de formularlas por parte de los entrevistadores, de hacer aclaraciones a los entrevistados o de registrar sus respuestas producen errores en las mediciones. Típicamente, cuanto más grande es el número de casos, menos error estadístico se obtiene, pero más error de medición se acumula. Los errores de medición suelen ser tan grandes y tan difíciles de especificar, que muchas veces relevamientos sobre poblaciones totales (por ejemplo, los censos) se corrigen con estimaciones realizadas sobre muestras (por ejemplo, las encuestas continuas de hogares) en cuya aplicación participa personal especializado. De modo que, aunque resulte contraintuitivo, las buenas muestras suelen ser más precisas que los relevamientos sobre poblaciones totales.
Solemos utilizar muestras muy pequeñas en términos relativos. Con una gota de sangre pueden determinarse con bastante precisión los niveles de glucosa en organismos como los humanos, que en su edad adulta portan algo más de cinco litros. Con 20 gramos de tierra puede conocerse la acidez de un suelo de decenas de metros cuadrados. Del mismo modo, una buena muestra de individuos humanos permite conocer con bastante precisión la distribución de comportamientos, opiniones o actitudes en toda la población del país que habitan. De hecho, utilizamos este procedimiento en la vida cotidiana todo el tiempo.
Muchos de nosotros, antes de entrar a la ducha, mojamos los dedos en el agua para evaluar si la temperatura es la que deseamos. Se trata de un conjunto muy pequeño de gotas de agua, en comparación con las que conforman los litros que descienden de la roseta. Cuando era niño, en la casa donde vivía se solía cocinar pasta los domingos al mediodía. En algún momento previo a la comida, alguien tenía que ir a probar la salsa para saber si estaba ácida. En tal caso se le agregaba un poco de azúcar. Para determinar la acidez de la salsa bastaba ingerir sólo parte del contenido de una cuchara de las de café. Eso también es muy poco en relación con los litros de salsa que se cocinan en una casa con una media de nueve comensales.
Es claro que para este tipo de muestras no basta un botón. Pero pareciera que unos pocos resultan suficientes. ¿Cómo es posible confiar en la investigación científica, como en la vida cotidiana, en inferencias poblacionales realizadas a partir de un puñado de casos? En este artículo nos adentramos en el no tan misterioso mundo de las muestras probabilísticas.
Atributos, no casos
Para comprender los aspectos lógicos involucrados en las inferencias a partir de muestras, debemos antes que nada asumir que aquellas no se realizan para conocer casos (como personas, partículas de salsa o gotas de agua que salen de rosetas) sino atributos que se manifiestan en casos.
Cada persona es única, eso es cierto. Pero también lo es cada gota de agua, como cada roca, cada estrella o cada mosca. Cuando ponemos la mano debajo de la ducha no pretendemos conocer la inmensa variedad de las gotas de agua, sino sólo un atributo en particular: su temperatura, aquí y ahora.
Supongamos que queremos estimar la proporción de personas adultas con opinión favorable a la derogación de la ley de urgente consideración (LUC). Mientras que los casos alcanzan los casi tres millones (uruguayos mayores de 18 años) la proporción en que el atributo ocurre en la población, que es lo que nos interesa, puede variar entre 0 y 1. O, si preferimos expresarlo en porcentajes, entre 0% y 100%. Se trata de un rango relativamente limitado, en especial si decidimos prescindir de los decimales. Del mismo modo, si nos interesa estimar la edad promedio (en años cumplidos) de una población, con independencia del tamaño que tenga, el valor se hallará dentro de un rango con una amplitud menor a la centena.
La distribución normal
Si estamos dispuestos a considerar asuntos humanos como atributos, idénticos formalmente a los que pueden observarse en el resto del mundo, nos encontramos en condiciones de conocer cómo funcionan las inferencias por muestreo. En lo que sigue utilizo como ejemplo la estimación de proporciones, aunque el razonamiento aplica, con leves ajustes, a promedios o cantidades absolutas.
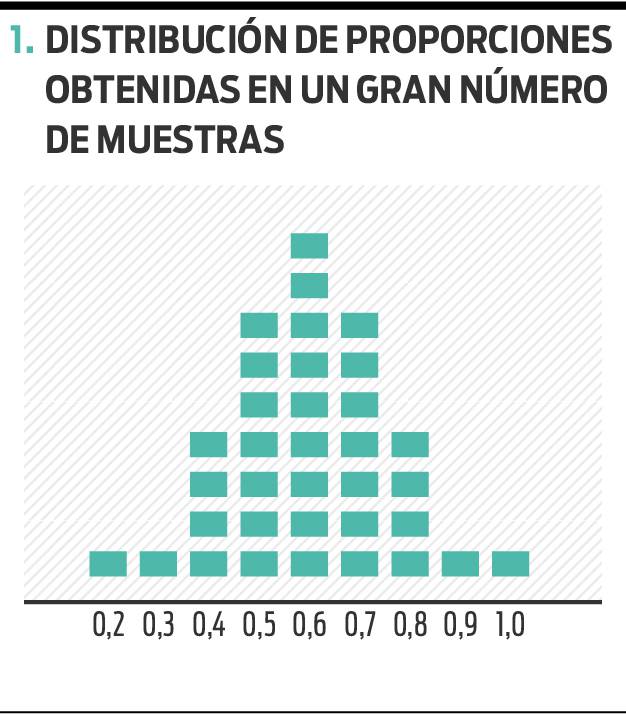
Piensa en una población del tipo que sea, como un conjunto de porotos blancos y negros en un saco. Quieres estimar la proporción de porotos negros en el saco. Tomas un puñado de porotos, cuentas los negros y divides ese número por el total de porotos que sacaste. ¿Puedes tener la seguridad de que esa proporción es la misma en el total de porotos dentro del saco? No. Si embargo, si sacas un número muy grande de puñados y estimas en cada caso la proporción de porotos negros, obtendrás una distribución de proporciones que asumirá la forma del gráfico 1.
Cómo leer el gráfico: Extrajiste muchas muestras del saco de porotos y calculaste en cada una la proporción de porotos negros. Ordenas los resultados obtenidos, ubicándolos en el lugar del eje que va de 0 (ningún poroto negro) a 1 (todos los porotos negros) según cuál haya sido la proporción de porotos negros que obtuviste en cada una. Tras la extracción de un número muy grande de muestras, las columnas asumirán una forma muy similar a la que muestra el gráfico.
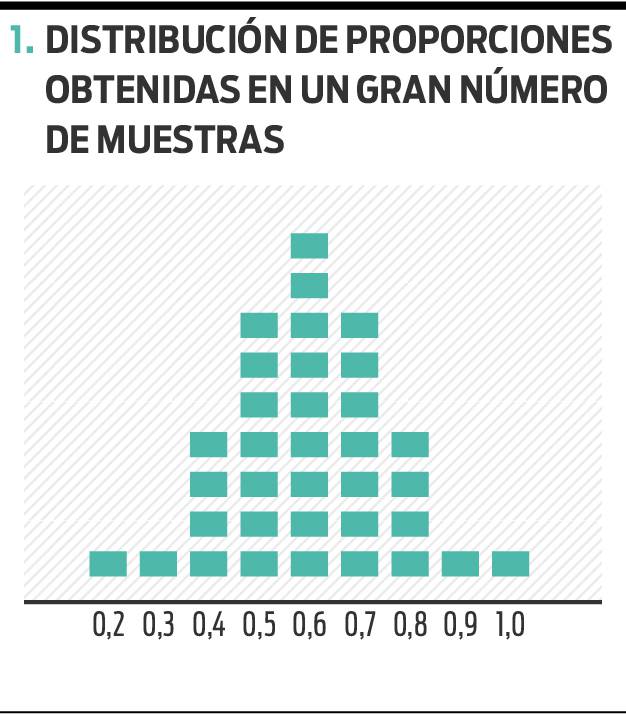
Si te tomas la molestia de contar todos los porotos blancos y todos los negros del saco, y calcular luego la proporción de estos últimos, comprobarás que el valor obtenido en la población es similar al que obtuviste en las muestras ubicadas en el centro de la distribución. En el ejemplo, 0,6 (o 60%) de porotos negros.
Conocemos la forma de este gráfico como distribución normal. Esta fascinante propiedad de la naturaleza es confirmada sistemáticamente desde hace decenas de años en los más diversos campos de la investigación científica. Destinamos recientemente un artículo a describirla.
Pero ¿de qué me sirve esta fascinante propiedad de la naturaleza para mi problema de los porotos? Si para conocer la proporción de los negros en el saco debo extraer miles de muestras, prefiero dar vuelta el saco y contar todos los porotos blancos y todos los negros. Tenemos una alternativa menos costosa. No es exacta, pero se aproxima. En un par de apartados te la presentamos.
Mezclar bien
Buena parte de las recetas de cocina dicen en un momento: ahora mezclamos bien todos los ingredientes. Pues en lo que refiere a las muestras probabilísticas, este es el requisito de inicio. Si los casos (en realidad, los valores que asume el atributo de interés, en los diferentes casos) no se encuentran bien mezclados, no sale la torta. Si podemos determinar la cantidad de glucosa en sangre analizando una gota es porque los niveles de glucosa se distribuyen uniformemente en todo el torrente sanguíneo (se encuentran bien mezclados). Lo mismo sucede con la salsa de la pasta del domingo. Pero como somos buenos en el arte de realizar inferencias a partir de muestras, solemos, de todos modos, revolver la salsa antes de probar una pizca.
En términos técnicos debemos asegurarnos de que todos los casos tengan una probabilidad conocida, y distinta de cero, de resultar seleccionados. Comúnmente se utiliza la expresión igual probabilidad de ser seleccionados. Resulta más sencillo entenderlo de ese modo: si la probabilidad de seleccionar un poroto negro es menor a la de seleccionar uno blanco (por ejemplo, porque los porotos negros están en el fondo del saco) las muestras que extraiga no resultarán muy confiables (voy a sacar sistemáticamente mayor proporción de porotos blancos). Pero conociendo la probabilidad de selección de cada tipo de poroto y con algunos cálculos posteriores, el problema se resuelve. Lo importante es que las chances de formar parte de la muestra sean conocidas.
El tamaño no importa
Bien. Extraemos unidades de una población, que han sido bien revueltas antes de la sacada. Vamos a estimar la proporción en que se manifiesta un atributo en esas unidades. ¿Cuántas debe incluir la muestra para que la estimación se aproxime al valor poblacional?
Muchas veces pensamos que eso depende del tamaño de la población. Si es chica requeriré una muestra chica; si es grande, una grande. No es así. Al menos no a partir de poblaciones con cierto número de casos (10.000 es un buen número).
Piénsalo de este modo: si para estimar el grado de acidez de un litro de salsa basta probar una cucharada, para estimar eso mismo en diez litros de salsa, ¿necesitas probar diez cucharadas? No, basta con una en ambos casos, siempre que hayas revuelto bien la salsa. Lo mismo vale para la gota de sangre en el caso de un humano bebé, un humano adulto o un elefante. En este caso el sistema circulatorio se encarga de mezclar. Por eso, aunque también resulte contraintuitivo, con una buena muestra aleatoria de igual tamaño puedes obtener estimaciones bastante precisas de comportamientos, opiniones o actitudes en Uruguay, México o India. El tamaño, en este asunto, no importa.
Lo que importa es la variedad
El secreto está en la heterogeneidad de la población en relación con el atributo cuya proporción, promedio o cantidad queremos estimar a partir una muestra.

Considera el gráfico 2A. Todas las muestras que extrajimos reportan el mismo valor. ¿Cómo puede ser? Existen dos posibilidades: o bien el tamaño de todas las muestras coincide con el de la población, o bien todos los casos de la población presentan el mismo valor en el atributo bajo estudio. Si, por ejemplo, todos los porotos del saco son negros, cada muestra que extraigas, con independencia de su tamaño, reportará una proporción igual a 1. Si quieres estimar el promedio de edad de una población integrada exclusivamente por personas de 18 años, cualquier muestra que extraigas te reportará una media de 18. En tales condiciones una muestra de un solo caso es suficiente para determinar con precisión el parámetro poblacional. Aquí sí, para muestra basta un botón.
La situación contraria corresponde a un máximo de heterogeneidad. El gráfico 2B representa una supuesta distribución de proporciones obtenidas de muestras extraídas de una población muy heterogénea respecto del atributo en cuestión.

Tenemos que conocer entonces el grado de heterogeneidad de la población.
Cuando se trata es de estimar promedios, las cosas se complican un poco. Para conocer cuán variadas son las edades en la población, necesito relevar todos los casos. Pero la idea es no hacerlo (si no, ¿qué sentido tiene extraer luego una muestra?). Existen, sin embargo, formas de aproximarse, indirectamente. Pero cuando tratamos con proporciones tenemos una solución sencilla: la mayor heterogeneidad corresponde a la proporción p = 0,5.
En nuestro ejemplo, la mitad de los porotos son negros (y la otra mitad blancos o distintos de negro, que en este caso significa lo mismo). El máximo grado de heterogeneidad se calcula como p x (1-p) lo cual equivale a decir 0,5 x 0,5 = 0,25. Cualquier valor distinto de p supone menor heterogeneidad y, por tanto, el producto de p x (1-p) devolverá un valor inferior a 0,25.
El problema no es equivocarnos, sino no saber cuánto
Piensa en la precisión de tus estimaciones muestrales como el volumen de un audio que se puede aumentar o reducir con dos perillas. La primera dice heterogeneidad del atributo; la segunda, tamaño de la muestra. En realidad, sólo puedes mover la segunda. Los atributos son más o menos heterogéneos en el mundo, con independencia de lo que tú hagas o dejes de hacer.
Como no sabes cuánta variabilidad tiene tu atributo en la población, una opción conservadora es subir esa perilla al máximo, es decir, suponer el máximo posible de heterogeneidad (cuando trabajamos con proporciones, poner la perilla en 0,25). Ahora sólo tienes que tomar una decisión respecto de la segunda perilla: el tamaño de tu muestra.
Cuanto mayores sean sus tamaños, siempre que sean aleatorias, menos variación observarás en los estimadores muestrales que obtengas tras las distintas extracciones. Vimos que, si ese tamaño es igual al de la población, las estimaciones coincidirán con el valor poblacional (primera alternativa de interpretación del gráfico 2A). Del mismo modo, cuanto menores sean sus tamaños, más indeterminada será la distancia entre las estimaciones muestrales y el valor poblacional. La distribución representada en el gráfico 2B puede considerarse una ilustración de resultados de muchas mediciones sobre muestras aleatorias muy pequeñas.
Sabes que la distribución de los promedios o proporciones que obtengas de todas las muestras aleatorias posibles que puedas extraer, de tamaño menor al de la población y con algún grado de heterogeneidad, tenderán a distribuirse normalmente (asumirán la forma de una campana).
La pregunta no es cómo hacer para que el resultado de una muestra en particular coincida con el de la población, sino qué tamaño de muestra necesitas para asegurarte de que de todas las muestras posibles que pudieras extraer, un porcentaje muy alto (como el 95% o el 99%) caerá en la parte central de la distribución y a una distancia no muy grande del valor poblacional (por ejemplo, no alejándose en menos o más de 3% de ese valor).

A lo primero le damos el nombre de intervalo de confianza. A lo segundo, margen de error. Para esto último basta considerar el valor que decidimos admitir y expresarlo como una proporción. Por ejemplo, si estamos dispuestos a obtener estimaciones con un error máximo de +-3% utilizamos el valor 0,03. Para lo primero tenemos un pequeño secreto (todos los cocineros lo tienen). El área de la distribución normal puede tratarse como una función, que devolverá valores específicos para cada subárea que definamos como nuestro intervalo de confianza. No necesitamos hacer cálculos complejos. Los valores pueden consultarse en una tabla que conocemos como distribución Z. Estos son los que corresponden a los intervalos de confianza más utilizados:
| Intervalo de confianza | Valor Z |
|---|---|
| 90% | 1,64 |
| 95% | 1,96 |
| 98% | 2,32 |
| 99% | 2,57 |
Resultado
Ya tenemos todos los ingredientes necesarios para determinar el tamaño de una muestra (m) de las que llamamos aleatorias simples (todos los casos, como las bolillas de un bolillero, tienen la misma probabilidad de selección) extraída de una población infinita (que en este contexto equivale a decir de tamaño desconocido). La fórmula es la siguiente:

Cómo leer la fórmula: Multiplicamos el valor del intervalo de confianza que estamos dispuestos a admitir, elevado al cuadrado (Z²) por el grado de heterogeneidad del atributo en la población (p x (1-p)). Dividimos el resultado por el margen de error máximo que aceptamos que tengan nuestras estimaciones, elevado al cuadrado (e²).
Si, por ejemplo, asumimos un intervalo de confianza de 95% (Z=1,96), suponemos la mayor heterogeneidad posible del atributo en la población (0,25) y aceptamos un margen de error de +-3% (0,03), obtenemos:

Este es el número mágico. Con 1.067 casos, extraídos con igual probabilidad de selección, de una población de tamaño desconocido, obtienes estimaciones de cualquier proporción poblacional, con un error máximo de +-3%, 95% de las veces.
Si el tamaño de la población es pequeño, te conviene utilizar una fórmula que considere ese número. Como es obvio, obtendrás muestras más pequeñas (para una población de 500 casos, seguro una muestra de tamaño menor a 500, aunque no tanto más pequeña). Pero a partir de los 10.000 casos, el tamaño de la población no afecta la estimación del tamaño muestral.
Si por razones de costo o de tiempo 1.067 es un número muy grande, puedes ajustar el intervalo de confianza o el margen de error. Por ejemplo, si estás dispuesto a admitir un error de +-5% en tus estimaciones, necesitas, en las condiciones descritas, sólo 385 casos.
Motivos para desconfiar
Tras la difusión de la célebre Ley de Murphy (si algo puede salir mal, saldrá mal) fueron descubiertas otras de similar tenor. Tom Gilb, ingeniero de sistemas de California, reportó la siguiente: no se debe confiar en las computadoras, pero menos aún en los seres humanos. La Ley de Gilb se aplica también a los problemas de muestreo: no se debe confiar en el azar, pero menos aún en las personas que trabajan con él.
La idea de intervalo de confianza es ilustrativa respecto del primer problema. Cuando afirmo que mi estimación se realiza con 95% de confianza estoy diciendo que de cada 100 muestras que pudiera extraer, en las mismas condiciones y con el mismo tamaño, en 95 de ellas el valor verdadero (el de la población total) estará contenido en el intervalo. Y en 5 no. Si mi muestra en particular es una de las muchas primeras o una de las pocas segundas, no lo puedo saber. Esta limitación es importante desde que las probabilidades no tienen nada que decir sobre el caso único: una vez extraída, la estimación se encontrará dentro del intervalo de confianza o fuera de él.
Sin embargo, como para arribar a conclusiones en la ciencia normalmente se realizan muchos estudios sobre muestras independientes, si estos arrojan valores similares para un mismo atributo, la probabilidad de que todos se hayan obtenido de muestras ubicadas en los extremos de la distribución se aproxima rápidamente a cero. Por ejemplo, la probabilidad de que tres muestras reporten valores ubicados fuera del intervalo (si asumimos uno de 95%, que los resultados de las tres muestras hayan caído fatalmente en el 5% restante) es 0,05 x 0,05 x 0,05 = 0,0001. Un argumento más en favor de replicar las observaciones y los experimentos, en lugar de conformarse con la revisión por pares, para dar por buenos resultados de investigación.
De modo que del azar debemos desconfiar, pero no mucho. Con los seres humanos las cosas son distintas. Al menos tres advertencias resultan necesarias para evaluar la calidad de las inferencias realizadas por muestreo.
A) Generalmente las muestras fallan porque no se respetan los procedimientos de selección aleatoria. Con cada vez más frecuencia leemos, por ejemplo, resultados de encuestas realizadas a través de redes sociales, sobre las que se intenta hacer inferencias para grandes poblaciones. ¿Todos los integrantes de esas grandes poblaciones tienen una probabilidad conocida y distinta de cero de haber sido seleccionados para esa encuesta? Si aplicas una encuesta entre tus amigos de Facebook, es claro que no. Todos quienes no sean amigos tuyos tienen probabilidad cero de resultar encuestados. Pero no es necesario llegar a tales extremos. Los humanos hemos desarrollado estrategias menos transparentes para hacer trampas en este sentido. La selección por cuotas (un procedimiento lógicamente insostenible por el cual se seleccionan casos atípicos, pero incluyendo intencionalmente en la muestra los que reproduzcan una distribución similar para un par de atributos como el sexo y la edad) es generalmente utilizada por empresas de opinión pública y de investigación de mercados.
Este es el primer aspecto a prestar atención, al cual nos referimos antes: si los ingredientes no fueron bien mezclados, no sale la torta.
B) Cuando se calcula un tamaño de muestra, con un intervalo de confianza y un margen de error específicos, se considera el total de la población. El objetivo es determinar la confiabilidad de la estimación que se realizará para una proporción, promedio o cantidad, en la población total. Si luego decido reportar valores de subpoblaciones, debo recalcular los márgenes de error. Supongamos que con 1.067 casos obtengo que 40% de los uruguayos habilitados para votar tiene opinión favorable a la derogación de la LUC. El resultado debe leerse como que entre 37% y 43% de los potenciales electores tiene esa opinión, a 95% de confianza. Luego reporto esa proporción (expresada como porcentaje) para Montevideo, afirmando que en la capital tal opinión asciende a 50%. En este caso estoy trabajando con una muestra más pequeña. Si en su diseño se mantuvo la distribución de población en nuestro país, esta submuestra incluirá a aproximadamente 394 casos (37% de los electores del país). Recuerda que el tamaño de las muestras no se ve afectado por el tamaño de las poblaciones, siempre que sean grandes. Con 394 casos, el margen de error aumenta a +-5%. De modo que el último resultado debiera reportarse como: en Montevideo, entre 45% y 55% de los potenciales votantes tiene opinión favorable a la derogación de la ley.
Es habitual que en la presentación de resultados de investigación se reporten valores obtenidos de submuestras de tamaño aún mucho más pequeño (por ejemplo, personas jóvenes, de sexo femenino, que residen en Montevideo), lo que conduce a márgenes de error tan grandes que hacen imposible realizar cualquier inferencia con seguridad.
Segundo aspecto a considerar: ¿sobre qué muestra efectiva se realizan las estimaciones?
C) Finalmente, hay que recordar que a los errores estadísticos se suman los de medición. Los casos de una muestra pueden ser seleccionados aleatoriamente, su tamaño puede ser suficiente para hacer inferencias con un amplio intervalo de confianza y un bajo margen de error, pero si en la recolección de datos existen problemas, tampoco sale la torta. Los errores de medición son, por lo general, más peligrosos que los estadísticos. No porque sean mayores, sino porque no podemos determinar con precisión cuál es su magnitud. Y siempre se suman a los estadísticos, dando por resultado un error total. Siendo indeterminado el valor de uno de los términos de la suma (el error de medición), también lo es su resultado.
Tercer aspecto a tener en cuenta: evalúa las competencias en materia de medición de la institución o empresa que reporta los hallazgos.
Agradezco los valiosos comentarios de la licenciada en Estadística Ana Coímbra a la primera versión de este artículo.